
URLs
In a nutshell, the app shell architecture involves aggressively caching static assets (the bare minimum of UI and functionality) and then loading the actual content dynamically, using JavaScript. Most modern JavaScript SPA frameworks encourage something resembling this approach, and the separation of logic and content in this way benefits both speed and usability. Interactions feel instantaneous, much like those on a native app, and data usage can be highly economical.
As I alluded to in the introduction, a heavy reliance on client-side JavaScript is a problem for SEO. Historically, many of these issues centered around the fact that while search crawlers require unique URLs to discover and index content, single page apps don’t need to change the URL for each state of the application or website (hence the phrase ‘single page’). The reliance on fragment identifiers — which aren’t sent as part of an HTTP request — to dynamically manipulate content without reloading the page was a major headache for SEO. Legacy solutions involved replacing the hash with a so-called hashbang (#!) and the _escaped_fragment_ parameter, a hack which has long-since been deprecated and which we won’t be exploring today.
Thanks to the HTML5 history API and pushState method, we now have a better solution. The browser’s URL bar can be changed using JavaScript without reloading the page, thereby keeping it in sync with the state of your application or site and allowing the user to make effective use of the browser’s ‘back’ button. While this solution isn’t a magic bullet — your server must be configured to respond to requests for these deep URLs by loading the app in its correct initial state — it does provide us with the tools to solve the problem of URLs in SPAs.
The bigger problem facing SEO today is actually much easier to understand: rendering content, namely when and how it gets done.
Rendering content
Note that when I refer to rendering here, I’m referring to the process of constructing the HTML. We’re focusing on how the actual content gets to the browser, not the process of drawing pixels to the screen.
In the early days of the web, things were simpler on this front. The server would typically return all the HTML that was necessary to render a page. Nowadays, however, many sites which utilize a single page app framework deliver only minimal HTML from the server and delegate the heavy lifting to the client (be that a user or a bot). Given the scale of the web this requires a lot of time and computational resource, and as Google made clear at its I/O conference in 2018, this poses a major problem for search engines:
“The rendering of JavaScript-powered websites in Google Search is deferred until Googlebot has resources available to process that content.”
On larger sites, this second wave of indexation can sometimes be delayed for several days. On top of this, you are likely to encounter a myriad of problems with crucial information like canonical tags and metadata being missed completely. I would highly recommend watching the video of Google’s excellent talk on this subject for a rundown of some of the challenges faced by modern search crawlers.
Google is one of the very few search engines that renders JavaScript at all. What’s more, it does so using a web rendering service that until very recently was based on Chrome 41 (released in 2015). Obviously, this has implications outside of just single page apps, and the wider subject of JavaScript SEO is a fascinating area right now. Rachel Costello’s recent white paper on JavaScript SEO is the best resource I’ve read on the subject, and it includes contributions from other experts like Bartosz Góralewicz, Alexis Sanders, Addy Osmani, and a great many more.
For the purposes of this article, the key takeaway here is that in 2019 you cannot rely on search engines to accurately crawl and render your JavaScript-dependent web app. If your content is rendered client-side, it will be resource-intensive for Google to crawl, and your site will underperform in search. No matter what you’ve heard to the contrary, if organic search is a valuable channel for your website, you need to make provisions for server-side rendering.
But server-side rendering is a concept which is frequently misunderstood…
“Implement server-side rendering”
This is a common SEO audit recommendation which I often hear thrown around as if it were a self-contained, easily-actioned solution. At best it’s an oversimplification of an enormous technical undertaking, and at worst it’s a misunderstanding of what’s possible/necessary/beneficial for the website in question. Server-side rendering is an outcome of many possible setups and can be achieved in many different ways; ultimately, though, we’re concerned with getting our server to return static HTML.
So, what are our options? Let’s break down the concept of server-side rendered content a little and explore our options. These are the high-level approaches which Google outlined at the aforementioned I/O conference:
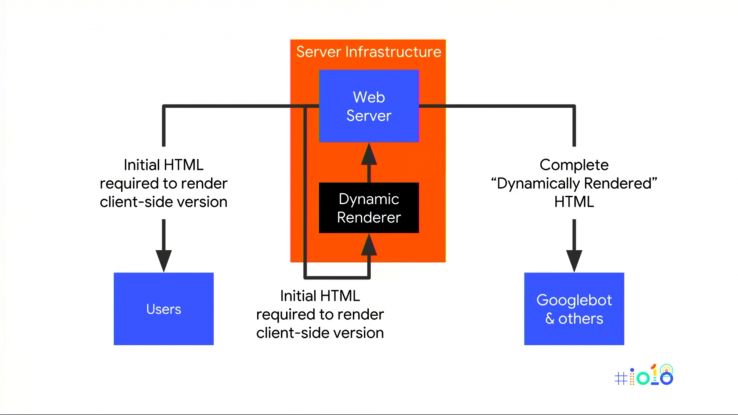
- Dynamic Rendering — Here, normal browsers get the ‘standard’ web app which requires client-side rendering while bots (such as Googlebot and social media services) are served with static snapshots. This involves adding an additional step onto your server infrastructure, namely a service which fetches your web app, renders the content, then returns that static HTML to bots based on their user agent (i.e. UA sniffing). Historically this was done with a service like PhantomJS (now deprecated and no longer developed), while today Puppeteer (headless Chrome) can perform a similar function homes for sale. The main advantage is that it can often be bolted into your existing infrastructure.
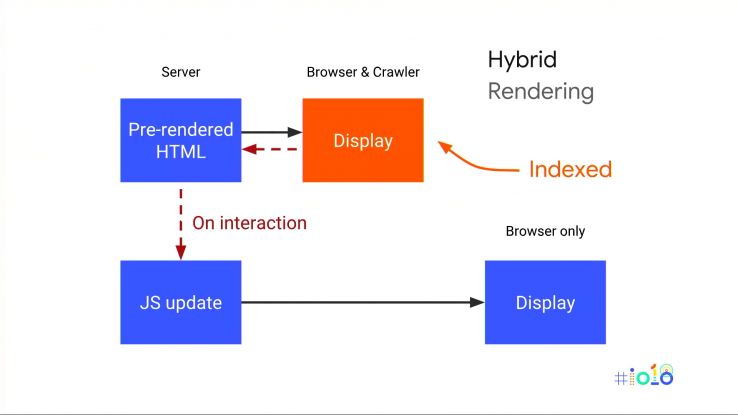
- Hybrid Rendering — This is Google’s long-term recommendation, and it’s absolutely the way to go for newer site builds. In short, everyone — bots and humans — get the initial view served as fully-rendered static HTML. Crawlers can continue to request URLs in this way and will get static content each time, while on normal browsers, JavaScript takes over after the initial page load. This is a great solution in theory, and comes with many other advantages for speed and usability too; more on that soon.
The latter is cleaner, doesn’t involve UA sniffing, and is Google’s long-term recommendation. It’s also worth clarifying that ‘hybrid rendering’ is not a single solution — it’s an outcome of many possible approaches to making static prerendered content available server-side. Let’s break down how a couple of ways such an outcome can be achieved.
Isomorphic/universal apps
This is one way in which you might achieve a ‘hybrid rendering’ setup. Isomorphic applications use JavaScript which runs on both the server and the client. This is made possible thanks to the advent of Node.js, which – among many other things – allows developers to write code which can run on the backend as well as in the browser.
Typically you’ll configure your framework (React, Angular Universal, whatever) to run on a Node server, prerendering some or all of the HTML before it’s sent to the client. Your server must, therefore, be configured to respond to deep URLs by rendering HTML for the appropriate page. In normal browsers, this is the point at which the client-side application will seamlessly take over. The server-rendered static HTML for the initial view is ‘rehydrated’ (brilliant term) by the browser, turning it back into a single page app and executing subsequent navigation events with JavaScript.
Done well, this setup can be fantastic since it offers the usability benefits of client-side rendering, the SEO advantages of server-side rendering, and a rapid first paint (even if Time to Interactive is often negatively impacted by the rehydration as JS kicks in). For fear of oversimplifying the task, I won’t go into too much more detail here, but the key point is that while isomorphic JavaScript / true server-side rendering can be a powerful solution, it is often enormously complex to set up.
So, what other options are there? If you can’t justify the time or expense of a full isomorphic setup, or if it’s simply overkill for what you’re trying to achieve, are there any other ways you can reap the benefits of the single page app model — and hybrid rendering setup — without sabotaging your SEO?
Prerendering/JAMstack
Having rendered content available server-side doesn’t necessarily mean that the rendering process itself needs to happen on the server. All we need is for rendered HTML to be there, ready to serve to the client; the rendering process itself can happen anywhere you like. With a JAMstack approach, rendering of your content into HTML happens as part of your build process.
I’ve written about the JAMstack approach before. By way of a quick primer, the term stands for JavaScript, APIs, and markup, and it describes a way of building complex websites without server-side software. The process of assembling a site from front-end component parts — a task a traditional site might achieve with WordPress and PHP — is executed as part of the build process, while interactivity is handled client-side using JavaScript and APIs.
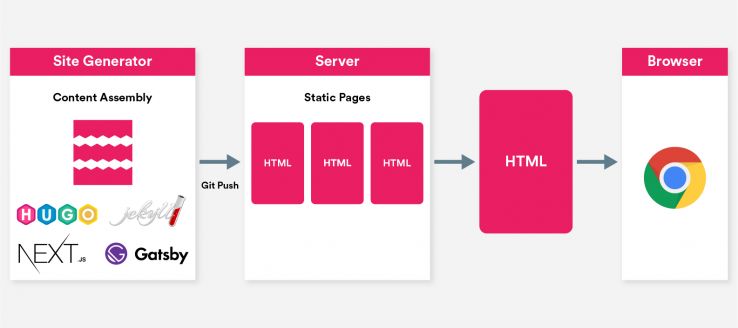
Think of it this way: everything lives in your Git repository. Your content is stored as plain text markdown files (editable via a headless CMS or other API-based solution) and your page templates and assembly logic are written in Go, JavaScript, Ruby, or whatever language your preferred site generator happens to use. Your site can be built into static HTML on any computer with the appropriate set of command line tools before it’s hosted anywhere. The resulting set of easily-cached static files can often be securely hosted on a CDN for next to nothing.
I honestly think static site generators – or rather the principles and technologies which underpin them — are the future. There’s every chance I’m wrong about this, but the power and flexibility of the approach should be clear to anyone who’s used modern npm-based automation software like Gulp or Webpack to author their CSS or JavaScript. I’d challenge anyone to test the deep Git integration offered by specialist webhost Netlify in a real-world project and still think that the JAMstack approach is a fad.
The significance of a JAMstack setup to our discussion of single page apps and prerendering should be fairly obvious. If our static site generator can assemble HTML based on templates written in Liquid or Handlebars, why can’t it do the same with JavaScript?
There is a new breed of static site generator which does just this. Frequently powered by React or Vue.js, these programs allow developers to build websites using cutting-edge JavaScript frameworks and can easily be configured to output SEO-friendly, static HTML for each page (or ‘route’). Each of these HTML files is fully rendered content, ready for consumption by humans and bots, and serves as an entry point into a complete client-side application (i.e. a single page app). This is a perfect execution of what Google termed “hybrid rendering”, though the precise nature of the pre-rendering process sets it quite apart from an isomorphic setup.
A great example is GatsbyJS, which is built in React and GraphQL. I won’t go into too much detail, but I would encourage everyone who’s read this far to check out their homepage and excellent documentation. It’s a well-supported tool with a reasonable learning curve, an active community (a feature-packed v2.0 was released in September), an extensible plugin-based architecture, rich integrations with many CMSs, and it allows developers to utilize modern frameworks like React without sabotaging their SEO. There’s also Gridsome, based on VueJS, and React Static which — you guessed it — uses React.
Enterprise-level adoption of these platforms looks set to grow; GatsbyJS was used by Nike for their Just Do It campaign, Airbnb for their engineering site airbnb.io, and Braun have even used it to power a major e-commerce site. Finally, our friends at SEOmonitor used it to power their new website.
But that’s enough about single page apps and JavaScript rendering for now. It’s time we explored the second of our two key technologies underpinning PWAs. Promise you’ll stay with me to the end (haha, nerd joke), because it’s time to explore Service Workers.