
First of all, I should clarify that the two technologies we’re exploring — SPAs and service workers — are not mutually exclusive. Together they underpin what we commonly refer to as a Progressive Web App, yes, but it’s also possible to have a PWA which isn’t an SPA. You could also integrate a service worker into a traditional static website (i.e. one without any client-side rendered content), which is something I believe we’ll see happening a lot more in the near future. Finally, service workers operate in tandem with other technologies like the Web App Manifest, something that my colleague Maria recently explored in more detail in her excellent guide to PWAs and SEO.
Ultimately, though, it is service workers which make the most exciting features of PWAs possible. They’re one of the most significant changes to the web platform in its history, and everyone whose job involves building, maintaining, or auditing a website needs to be aware of this powerful new set of technologies. If, like me, you’ve been eagerly checking Jake Archibald’s Is Service Worker Readypage for the last couple of years and watching as adoption by browser vendors has grown, you’ll know that the time to start building with service workers is now.

We’re going to explore what they are, what they can do, how to implement them, and what the implications are for SEO.
What can service workers do?
A service worker is a special kind of JavaScript file which runs outside of the main browser thread. It sits in-between the browser and the network, and its powers include:
- Intercepting network requests and deciding what to do with them programmatically. The worker might go to network as normal, or it might rely solely on the cache. It could even fabricate an entirely new response from a variety of sources. That includes constructing HTML.
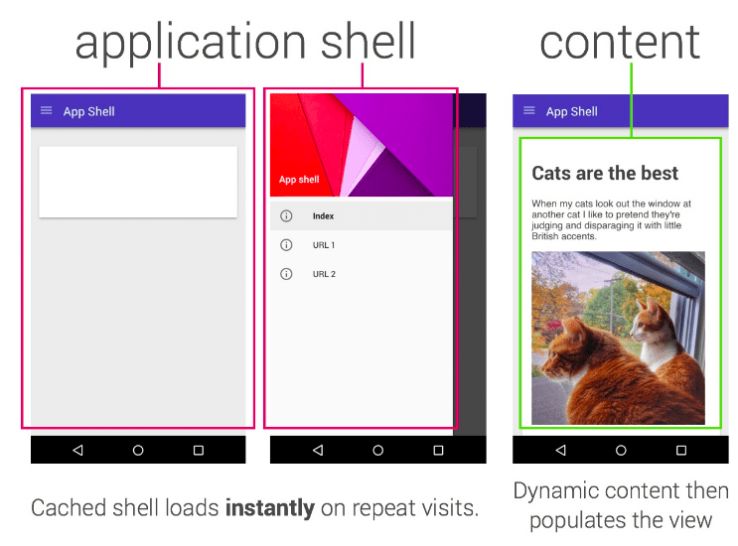
- Preloading files during service worker installation. For SPAs this commonly includes the ‘app shell’ we discussed earlier, while simple static websites might opt to preload all HTML, CSS, and JavaScript, ensuring basic functionality is maintained while offline.
- Handling push notifications, similar to a native app. This means websites can get permission from users to deliver notifications, then rely on the service worker to receive messages and execute them even when the browser is closed.
- Executing background sync, deferring network operations until connectivity has improved. This might be an ‘outbox’ for a webmail service or a photo upload facility. No more “request failed, please try again later” – the service worker will handle it for you at an appropriate time.
The benefits of these kinds of features go beyond the obvious usability perks. As well as driving adoption of HTTPS across the web (all the major browsers will only register service workers on the secure protocol), service workers are transformative when it comes to speed and performance. They underpin new approaches and ideas like Google’s PRPL Pattern, since we can maximize caching efficiency and minimize reliance on the network. In this way, service workers will play a key role in making the web fast and accessible for the next billion web users.
So yeah, they’re an absolute powerhouse.
Implementing a service worker
Rather than doing a bad job of writing a basic tutorial here, I’m instead going to link to some key resources. After all, you are in the best position to know how deep your understanding of service workers needs to be.
The MDN Docs are a good place to learn more about service workers and their capabilities. If you’re already confident with the essentials of web development and enjoy a learn-by-doing approach, I’d highly recommend completing Google’s PWA training course. It includes a whole practical exerciseon service workers, which is a great way to familiarize yourself with the basics. If ES6 and promises aren’t yet a part of your JavaScript repertoire, prepare for a baptism of fire.
They key thing to understand — and which you’ll realize very quickly once you start experimenting — is that service workers hand over an incredible level of control to developers. Unlike previous attempts to solve the connectivity conundrum (such as the ill-fated AppCache), service workers don’t enforce any specific patterns on your work; they’re a set of tools for you to write your own solutions to the problems you’re facing.
One consequence of this is that they can be very complex. Registering and installing a service worker is not a simple exercise, and any attempts to cobble one together by copy-pasting from StackExchange are doomed to failure (seriously, don’t do this). There’s no such thing as a ready-made service worker for your site — if you’re to author a suitable worker, you need to understand the infrastructure, architecture, and usage patterns of your website. Uncle Ben, ever the web development guru, said it best: with great power comes great responsibility.
One last thing: you’ll probably be surprised how many sites you visit are already using a service worker. Head to chrome://serviceworker-internals/ in Chrome or about:debugging#workers in Firefox to see a list.
Service workers and SEO
In terms of SEO implications, the most relevant thing about service workers is probably their ability to hijack requests and modify or fabricate responses using the Fetch API. What you see in ‘View Source’ and even on the Network tab is not necessarily a representation of what was returned from the server. It might be a cached response or something constructed by the service worker from a variety of different sources.
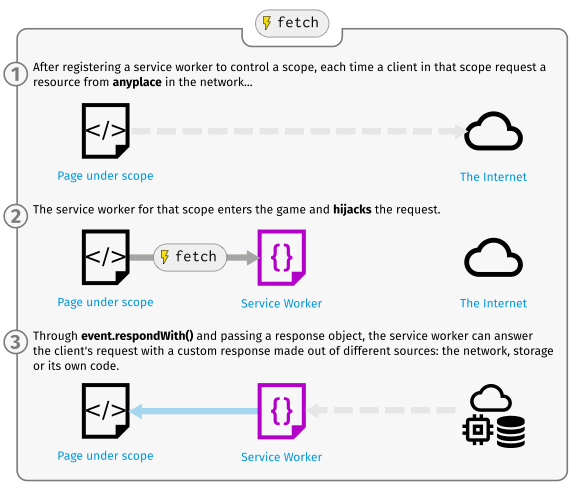
Here’s a practical example:
- Head to the GatsbyJS homepage
- Hit the link to the ‘Docs’ page.
- Right-click – View Source
No content, right? Just some inline scripts and styles and empty HTML elements — a classic client-side JavaScript app built in React. Even if you open the Network tab and refresh the page, the Preview and Response tabs will tell the same story. The actual content only appears in the Element inspector, because the DOM is being assembled with JavaScript.
Now run a curl request for the same URL (https://www.gatsbyjs.org/docs/), or fetch the page using Screaming Frog. All the content is there, along with proper title tags, canonicals, and everything else you might expect from a page rendered server-side. This is what a crawler like Googlebot will see too.
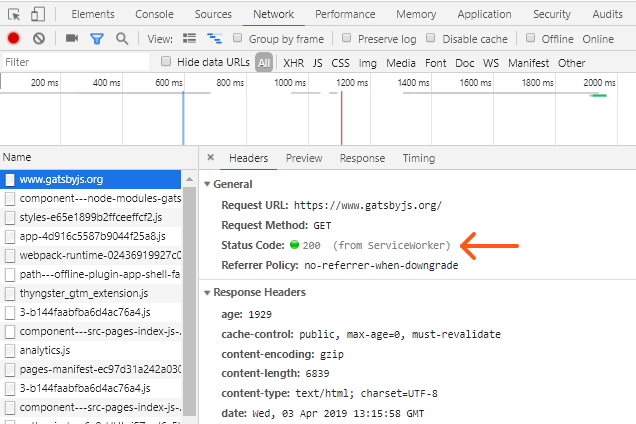
This is because the website uses hybrid rendering and a service worker — installed in your browser — is handling subsequent navigation events. There is no need for it to fetch the raw HTML for the Docs page from the server because the client-side application is already up-and-running – thus, View Source shows you what the service worker returned to the application, not what the network returned. Additionally, these pages can be reloaded while you’re offline thanks to the service worker’s effective use of the cache.
You can easily spot which responses came from the service worker using the Network tab — note the ‘from ServiceWorker’ line below.
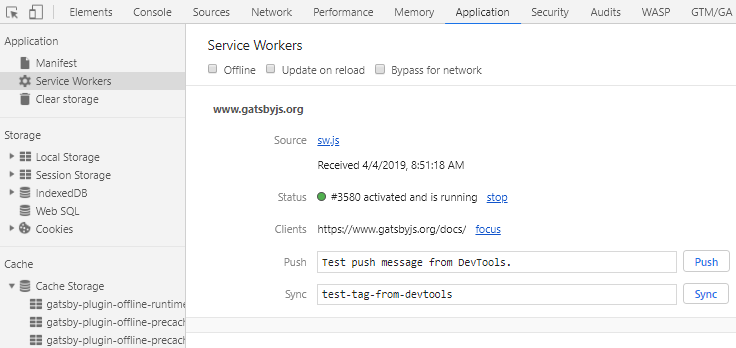
On the Application tab, you can see the service worker which is running on the current page along with the various caches it has created. You can disable or bypass the worker and test any of the more advanced functionality it might be using. Learning how to use these tools is an extremely valuable exercise; I won’t go into details here, but I’d recommend studying Google’s Web Fundamentals tutorial on debugging service workers.
I’ve made a conscious effort to keep code snippets to a bare minimum in this article, but grant me this one. I’ve put together an example which illustrates how a simple service worker might use the Fetch API to handle requests and the degree of control which we’re afforded:
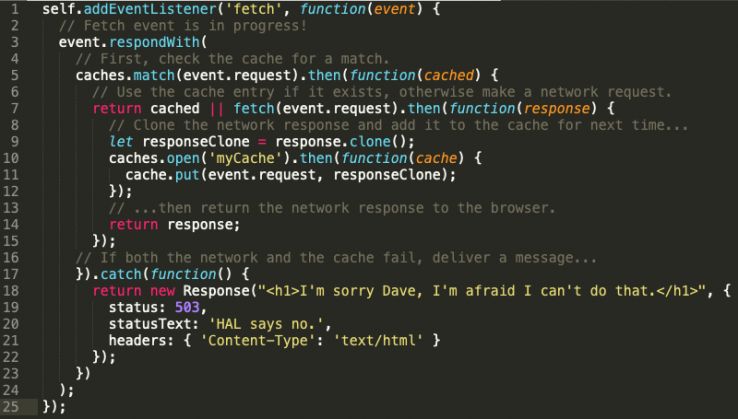
The result:
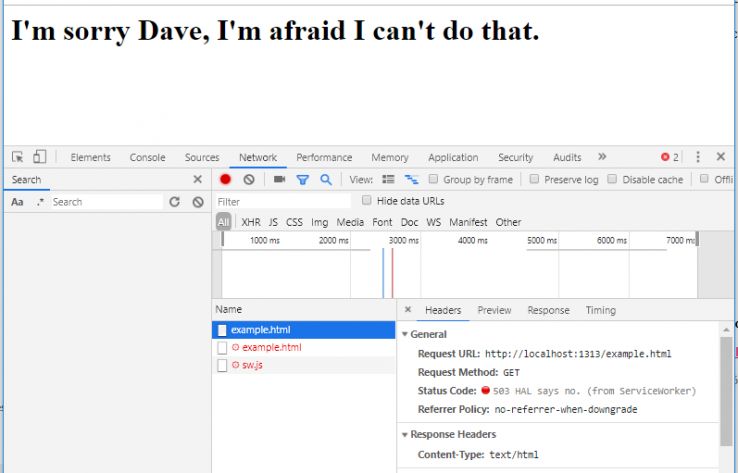
I hope that this (hugely simplified and non-production ready) example illustrates a key point, namely that we have extremely granular control over how resource requests are handled. In the example above we’ve opted for a simple try-cache-first, fall-back-to-network, fall-back-to-custom-page pattern, but the possibilities are endless. Developers are free to dictate how requests should be handled based on hostnames, directories, file types, request methods, cache freshness, and loads more. Responses – including entire pages – can be fabricated by the service worker. Jake Archibald explores some common methods and approaches in his Offline Cookbook.
The time to learn about the capabilities of service workers is now. The skillset required for modern technical SEO has a fair degree of overlap with that of a web developer, and today, a deep understanding of the dev tools in all major browsers – including service worker debugging – should be regarded as a prerequisite.